
Lasso (statistiques)
| Type |
Méthode statistique (d) |
|---|---|
| Inventeur | |
| Date d'invention |
En statistiques, le lasso est une méthode de contraction des coefficients de la régression développée par Robert Tibshirani dans un article publié en 1996 intitulé Regression shrinkage and selection via the lasso[1].
Le nom est un acronyme anglais : Least Absolute Shrinkage and Selection Operator[1],[2].
Bien que cette méthode fut utilisée à l'origine pour des modèles utilisant l'estimateur usuel des moindres carrés, la pénalisation lasso s'étend facilement à de nombreux modèles statistiques tels que les modèles linéaires généralisés, les modèles à risque proportionnel, et les M-estimateurs. La capacité du lasso à sélectionner un sous-ensemble de variables est due à la nature de la contrainte exercée sur les coefficients et peut s'interpréter de manière géométrique, en statistique bayésienne ou analyse convexe.
Présentation formelle[modifier | modifier le code]
Soit , le vecteur contenant les variables explicatives associées à l'individu , la réponse associée et les coefficients à estimer.




Modèle linéaire[modifier | modifier le code]
Dans le cadre d'un modèle linéaire standard, les coefficients sont obtenus par minimisation de la somme des carrés des résidus.
Avec la méthode lasso, le vecteur de coefficients est également obtenu en minimisant la somme des carrés des résidus mais sous une contrainte supplémentaire :


Le paramètre contrôle le niveau de régularisation des coefficients estimés.

Il s'agit d'une pénalisation de la norme des coefficients . Cette contrainte va contracter la valeur des coefficients (tout comme la régression ridge) mais la forme de la pénalité va permettre à certains coefficients de valoir exactement zéro (à l'inverse de la régression ridge).



De plus, dans des cas où le nombre de variables est supérieur au nombre d'individus , le lasso en sélectionnera au plus [3].


On peut écrire aussi la version lagrangienne de ce problème :

avec le paramètre de régularisation. Ce paramètre est relié au paramètre par une relation dépendante des données.


Écriture vectorielle[modifier | modifier le code]



Soit la matrice contenant en ligne les individus, . Le lasso s'écrit généralement sous forme vectorielle, en considérant les variables centrées afin d'enlever la constante du problème :




avec la norme


La version vectorielle pour le lagrangien, quant à elle, s'écrit :

Cas orthonormal[modifier | modifier le code]
Dans le cas où la matrice est telle que , le lasso a une solution explicite. L'estimateur lasso correspond alors à un seuillage doux de la solution des moindres carrées. Notons la solution des moindres carrées. La solution du lasso pour est :































Conditions de Karush-Kuhn-Tucker[modifier | modifier le code]
Les conditions de Karush-Kuhn-Tucker sont des conditions qu'une solution d'un problème d'optimisation sous contraintes doit vérifier pour être optimale. Dans le cas de la version linéaire du lasso, les conditions du premier ordre sont pour :

![{\displaystyle s_{j}\in \left\{{\begin{array}{lll}\operatorname {sgn}(({\hat {\beta }}_{\lambda }^{L})_{j})&{\mbox{si}}&({\hat {\beta }}_{\lambda }^{L})_{j}\not =0\\{[-1;1]}&{\mbox{si}}&({\hat {\beta }}_{\lambda }^{L})_{j}=0\end{array}}\right.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/767dec757217c2f51a53b678b688c72129ff40e8)
avec la ieme colonne de la matrice et appartenant au sous-différentiel de la fonction [3].



Cas général[modifier | modifier le code]
Le lasso n'est pas uniquement restreint à la régression linéaire, il peut être également utilisé avec les modèles linéaires généralisés permettant ainsi de faire de la régression logistique pénalisée. L'écriture vectorielle de la forme lagrangienne est :

avec une fonction objectif.

Par exemple, pour une régression logistique, on a :
- .

Avantages et limites du lasso[modifier | modifier le code]
Les principaux avantages du lasso sont :
- Grande dimension : le lasso fonctionne dans les cas où le nombre d'individus est inférieur au nombre de variables , si toutefois un faible nombre de ces variables a une influence sur les observations (hypothèse de parcimonie). Cette propriété n'est pas vraie dans le cas de la régression linéaire classique avec un risque associé qui augmente comme la dimension de l'espace des variables même si l'hypothèse de parcimonie est vérifiée.
- Sélection parcimonieuse : le lasso permet de sélectionner un sous-ensemble restreint de variables (dépendant du paramètre ). Cette sélection restreinte permet souvent de mieux interpréter un modèle (rasoir d'Ockham).
- Consistance de la sélection : lorsque le vrai vecteur solution est creux , c'est-à-dire que seul un sous-ensemble de variables est utilisé pour la prédiction, sous de bonnes conditions, le lasso sera en mesure de sélectionner ces variables d'intérêts avant toutes autres variables[4].



Par contre, certaines limites du lasso ont été démontrées :
- Les fortes corrélations : si des variables sont fortement corrélées entre elles et qu'elles sont importantes pour la prédiction, le lasso en privilégiera une au détriment des autres. Un autre cas, où les corrélations posent problème, est quand les variables d'intérêts sont corrélées avec d'autres variables. Dans ce cas, la consistance de la sélection du lasso n'est plus assurée[4].
- La très grande dimension : lorsque notamment la dimension est trop élevée ( très grand comparé à ) ou le vrai vecteur n'est pas suffisamment creux (trop de variables d'intérêts), le lasso ne pourra pas retrouver l'ensemble de ces variables d'intérêts[5].

Algorithmes de Résolution[modifier | modifier le code]
Comme la fonction objectif du lasso n'est pas différentiable (car la norme n'est pas différentiable en 0), différents algorithmes ont été développés afin d'en trouver les solutions. Parmi ces algorithmes, on retrouve notamment le Least-Angle Regression (LARS)[6] et la descente de coordonnées circulaire [7].
Applications[modifier | modifier le code]
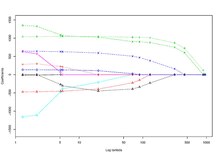
Le lasso est utilisé dans des problèmes de grande dimension (), un cas où des méthodes plus classiques ne fonctionnent pas. Le lasso dispose d'algorithmes peu coûteux en temps de calcul et de stockage, ce qui le rend d'autant plus populaire, comme en génomique où l'on peut être amené à traiter des jeux de données avec plusieurs centaines de milliers de variables.

En pratique, le lasso est testé pour différentes valeurs de . Un chemin solution représentant l'évolution des coefficients en fonction de est ainsi obtenu. La courbe d'un coefficient estimé en fonction de est linéaire par morceaux. Une fois ce chemin solution obtenu, une valeur de est choisie par des méthodes comme la validation croisée ou un critère d'information (AIC par exemple).
Extensions[modifier | modifier le code]
Un certain nombre de variantes du lasso ont été créées pour étendre la méthode à différents cas pratiques ou pour pallier certaines limitations du lasso. Sont présentées ici les variantes les plus courantes.
Elastic-Net[modifier | modifier le code]
L'Elastic-net[8] a été introduit afin de surmonter deux "limitations" du lasso. Premièrement, le lasso ne peut sélectionner qu'au plus variables dans le cas où . Deuxièmement, en présence d'un groupe de variables fortement corrélées, le lasso ne sélectionne généralement qu'une seule variable du groupe. L'idée est donc d'ajouter au lasso une pénalité ridge. Ainsi l'objectif de l'Elastic-Net est :

avec et .


Fused-lasso[modifier | modifier le code]
Le Fused-Lasso[9] permet de prendre en compte la spatialité des variables. Le principe est que les variables "proches" aient des coefficients estimés "proches". Cela est possible en pénalisant la norme de la différence de deux coefficients successifs. De la même manière que pénaliser la norme d'un coefficient a tendance à produire des coefficients égaux à 0, pénaliser la différence va favoriser l'égalité de deux coefficients successifs. L'objectif du Fused-Lasso est alors :

avec et .
Group-Lasso[modifier | modifier le code]
L'idée du Group-Lasso[10] est d'avoir une méthode fournissant une sélection parcimonieuse de groupes (fournis a priori) et non de variables. Soit , une partition des variables en groupes. On note , pour , le vecteur restreint aux éléments du groupe . L'objectif du Group-Lasso est :






avec , le paramètre de régularisation et , un poids associé au groupe (généralement ).



Notes et références[modifier | modifier le code]
- (en) Robert Tibshirani, « Regression shrinkage and selection via the lasso », Journal of the Royal Statistical Society. Series B, vol. 58, no 1, , p. 267-288
- Andrew Gelman, « Tibshirani announces new research result: A significance test for the lasso », sur Blog d'Andrew Gelman (consulté le )
- (en) Ryan Tibshirani, « The lasso problem and uniqueness », Electronic Journal of Statistics, vol. 7, no 0, , p. 1456-1490
- (en) Peng Zhao et Bin Yu, « On Model Selection Consistency of Lasso », The Journal of Machine Learning Research, vol. 7, , p. 2541-2563
- (en) Martin Wainwright et Bin Yu, « Sharp Thresholds for High-Dimensional and Noisy Sparsity Recovery Using -Constrained Quadratic Programming (Lasso) », IEEE Transactions on Information Theory, vol. 55, no 5, , p. 2183 - 2202
- (en) Bradley Efron, Trevor Hastie, Iain Johnstone et Robert Tibshirani, « Least angle regression », The Annals of Statistics, vol. 32, no 2, , p. 407-499
- (en) Jerome Friedman, Trevor Hastie et Robert Tibshirani, « Regularization Paths for Generalized Linear Models via Coordinate Descent », Journal of Statistical Software, vol. 33, no 1, , p. 1-22
- (en) Hui Zou et Trevor Hastie, « Regularization and variable selection via the elastic net », Journal of the Royal Statistical Society: Series B (Statistical Methodology), vol. 67, no 2, , p. 301-320
- (en) Robert Tibshirani, Michael Saunders, Saharon Rosset, Ji Zhu et Keith Knight, « Sparsity and smoothness via the fused lasso », Journal of the Royal Statistical Society: Series B (Statistical Methodology), vol. 67, no 1, , p. 91-108
- (en) Ming Yuan et Yi Lin, « Model Selection and Estimation in Regression with Grouped Variables », Journal of the Royal Statistical Society. Series B (statistical Methodology), vol. 68, no 1, , p. 49–67
Voir aussi[modifier | modifier le code]
Lien interne[modifier | modifier le code]
Liens externes[modifier | modifier le code]
- The Lasso Page sur le site web de Robert Tibshirani